2.8 Journalisation sous Alpine Linux¶
☕ À la machine à café de CorpTech
– « Cette nuit, le serveur a encore fait n’importe quoi. Je n’arrivais pas à me connecter. »
– « Aucune idée. Ce matin tout avait l’air normal. »
Note
Cette discussion pose une question simple à laquelle personne ne peut répondre : qu’est-ce qu’il s’est passé cette nuit ?
Le problème n’est pas tant que le serveur ait dysfonctionné, mais que, le lendemain, aucune information exploitable n’ait permis de comprendre ce qui s’est produit.
Le TP commence ici : comment disposer d’informations exploitables sur un événement passé ?
1. Observer des traces existantes¶
Avant toute configuration, on observe ce que le système conserve déjà.
logread
Des lignes apparaissent immédiatement. Elles proviennent de sources différentes : services, tâches planifiées, processus système, etc ...
Premier constat : le système produit des traces, et elles sont accessibles.
Second constat : À la lecture des lignes affichées par logread, vous avez (bien évidemment tout de suite ...) remarqué que les traces des log respectaient la même structure :
Une ligne = une entrée avec :
- date et heure,
- nom de la machine,
- priorité (
syslog.info,cron.info,user.notice) - tag, nom du service, programme à l'origine de la ligne suivi du PID entre []
- Le message
Hummm ... ces messages proviennent de programmes très différents et pourtant la syntaxe du log est toujours la même ...
Une coïncidence ? Comme pour la zone 51 officiellement non confirmée… un simple hasard ? Je ne crois pas…
Comparez deux lignes issues de services différents (cron et sshd).
Dec 21 22:30:18 alpine cron.info crond[2545]: crond (busybox 1.37.0) started, log level 8
Dec 21 22:32:54 alpine auth.info sshd[2293]: Server listening on 0.0.0.0 port 22.
→ même structure, mêmes champs, même ordre.
Sur Alpine Linux, ce rôle est assuré par le démon de journalisation syslogd (implémentation BusyBox), implémentation minimale du protocole Syslog. Ceci garantit un format de log cohérent et uniforme, quel que soit le programme à l’origine du message.
Maintenant que l'on a vu comment accéder aux logs géré par syslog, nous allons essayer d'en produire quelques-uns .
logger est une commande qui permet d’envoyer manuellement un message au système de journalisation.
Le message est traité exactement comme un log produit par un service (sshd, cron, etc.).
Principe de fonctionnement¶
Quand on exécute logger :
- le message est transmis au démon de journalisation (
syslogd), - il reçoit une origine (tag),
- un niveau de gravité,
- puis il est stocké (mémoire ou disque selon la configuration on verra ça après).
Utilisation minimale¶
logger "Message de test"
→ envoie un message simple,
→ le tag par défaut est le nom de l’utilisateur,
→ visible avec logread.
Définir clairement l’origine (tag)¶
logger -t test_log1 "Test de log : message manuel"
Vérification :
logread
Le message apparaît en fin de liste avec la même structure que les autres.
Dec 21 16:28:18 alpine user.notice test_log1: Test de log : message manuel
On peut également modifié le niveau de sévérité : L’option -p attend la forme facility.severity. (la liste des facility et severity est disponible dans le RFC syslog tableau 1 et 2 )
logger -t test_log2 -p user.warning "Test de log : niveau WARNING"
logger -t test_log3 -p user.emerg "Test de log : niveau EMERGENCY"
Vérifiez vos log:
logread
Bon voila, on ne s'étend pas sur ce sujet, mais comme ça si un jour vous avez besoin de logguer des événements, vous savez à qui vous adresser.
RFC 5424: The Syslog Protocol
Je vous laisse y jeter un oeil pour votre culture générale. https://www.rfc-editor.org/rfc/rfc5424.html
Configuration de syslog¶
Jusqu’ici, on a constaté que les logs respectent une convention commune d’écriture et qu’ils sont géré par syslogd. On a même généré quelques messages pour vérifier ce mécanisme. Mais la question de la machine à café reste entière: pourquoi tout semble fonctionner normalement ce matin, alors que le serveur a posé problème cette nuit ?
Donc la bonne question n’est pas "Existe t-il des logs ? " mais comment et où sont-ils enregistrés ?. La réponse se trouve dans la configuration de syslog, mais contrairement à d’autres services, il n’y a pas de fichier complexe à analyser. Sur Alpine, le comportement de syslogd est essentiellement déterminé par les options avec lesquelles le démon est lancé, options que l’on retrouve dans un seul fichier :
/etc/conf.d/syslog
Autrement dit, ici, la configuration n’est pas un ensemble de règles, mais une ligne d’options qu'il suffit de modifier pour changer complètement le mode de stockage des logs.
cat /etc/conf.d/syslog
Voila ce qu'on y trouve, rien de plus. Simplement l'option -C16
SYSLOGD_OPTS="-C16"
Si l'on faire un rapide;
syslogd --help
on voit l'option -C:
-C[size_kb] Log to shared mem buffer (use logread to read it)
Ce qui veut dire pour ceux qui ont du mal avec l'anglais, que avec l’option -C on demande à syslogd de stocker les logs en RAM...
Normalement ... vous auriez du au moins froncer un sourcil à la lecture de "stocker les logs en RAM" ? Non ...
Question à 1000 Euros
Qu’est-ce qui se passe si on redémarre la machine ?
Et ben faite le:
reboot
Et maintenant regardez vos logs avec logread ...

Vous commencez a comprendre ce qui c'est passé ... Regardez l’état des logs après redémarrage.
La RAM a été vidée à l’extinction de la machine, détruisant les données stockés dans la RAM. Avec cette configuration de syslogd, aucune trace ne pouvait survivre au redémarrage. Si le serveur a redémarré pendant la nuit, et que les logs étaient stockés uniquement en RAM, alors il est logique qu’aucune information ne soit disponible le matin.
Si on avait été mauvaise langue, on aurait répondu aux types de la machine à café :
« Ben quand on stocke les logs en RAM, on ne fait plus de l’administration système : on organise l’amnésie. » (sauf dans des cas bien précis, mais ça on ne leur dit pas)
Pour l'instant, corriger la situation consiste à modifier la configuration de syslogd pour qu’il écrive les logs sur disque et non dans la RAM, faute de quoi toute analyse après redémarrage restera impossible.
Activer la persistance des logs¶
Sur Alpine Linux, le service de journalisation correspond à l’implémentation BusyBox syslogd. Pourquoi est ce que je dis cela ? Parce ce que pour nous syslog est une version allégé intégré à busyBox. La configuration de BusyBox syslog n'est donc pas une vérité absolue valable sur toutes les distributions.
nano /etc/conf.d/syslog
Remplacer SYSLOGD_OPTS="-C16" par
SYSLOGD_OPTS=""
En supprimant l’option -C, on impose à syslogd d’écrire les logs sur le disque et non en mémoire. Le syslogd BusyBox, écrit les logs par défaut dans /var/log/messages.
Pour appliquer cette configuration il est nécessaire de redémarrer le service syslog:
rc-service syslog restart
Vérifier l’écriture sur disque
logger -t test_log1 "Test: écriture dans le fichier /var/log/messages"
cat /var/log/messages
Le log est maintenant écrit dans le fichier /var/log/messages:
Dec 21 22:30:53 alpine user.notice test_log1: Test: écriture dans le fichier /var/log/messages
Notez précisément l’heure de ce message, afin de le retrouver après le redémarrage.
Faite un redémarrage
reboot
Afficher a nouveau le log et fait une recherche à l'horaire que vous avez retenue... votre log est là !
Note
Rendre les logs persistants est un choix qui pose immédiatement d’autres questions :
- combien de temps conserver les logs ;
- quelle taille maximale autoriser ;
- que faire lorsque le disque se remplit.
Ces points relèvent, encore une fois, d’une politique de journalisation (rotation, archivage, purge), c’est-à-dire de choix qui impliquent des prises de responsabilité.
La rotation et l’archivage seront traités ultérieurement.
Arrêt du service de journalisation¶
On arrête volontairement le collecteur de logs :
rc-service syslog stop
On génère ensuite un message :
logger -t test_log1 "Test service arrêté"
Aucune nouvelle trace n’apparaît, ni dans logread, ni dans /var/log/messages.
Le message a bien été émis, mais il n’y a plus de collecteur actif pour l’enregistrer.
Lors de l’arrêt du service a bien provoquer un enregistrement dans le log:
Dec 21 23:49:20 alpine syslog.info syslogd exiting
MaisUne fois syslogd arrêté, plus rien ne surveille l'apparition de log.
Et le runlevel default ?¶
Ajouter syslogd au runlevel default garantit une chose, et une seule :
rc-update add syslog default
→ au prochain redémarrage, le service sera relancé.
En revanche, tant que le serveur n’est pas redémarré :
- le service reste arrêté,
- aucun log n’est collecté,
- et le système continue de fonctionner normalement.
Conclusion :
OpenRC garantit le retour d’un service au boot.
Il ne corrige ni les arrêts, ni les oublis, en cours de fonctionnement.
Un log n’est donc fiable que si toute la chaîne est active, en permanence.
L'outil lnav¶
lnav est un outil puissant d’analyse de logs en ligne de commande.Fonctionnalités pratiques de lnav :
- ouverture simultanée de plusieurs fichiers de logs dans une vue chronologique unique ;
- détection et mise en évidence automatiques des erreurs
- recherche rapide par mot-clé ou expression régulière ;
- filtrage dynamique des lignes affichées ;
-
interrogation des logs via des requêtes SQL intégrées.
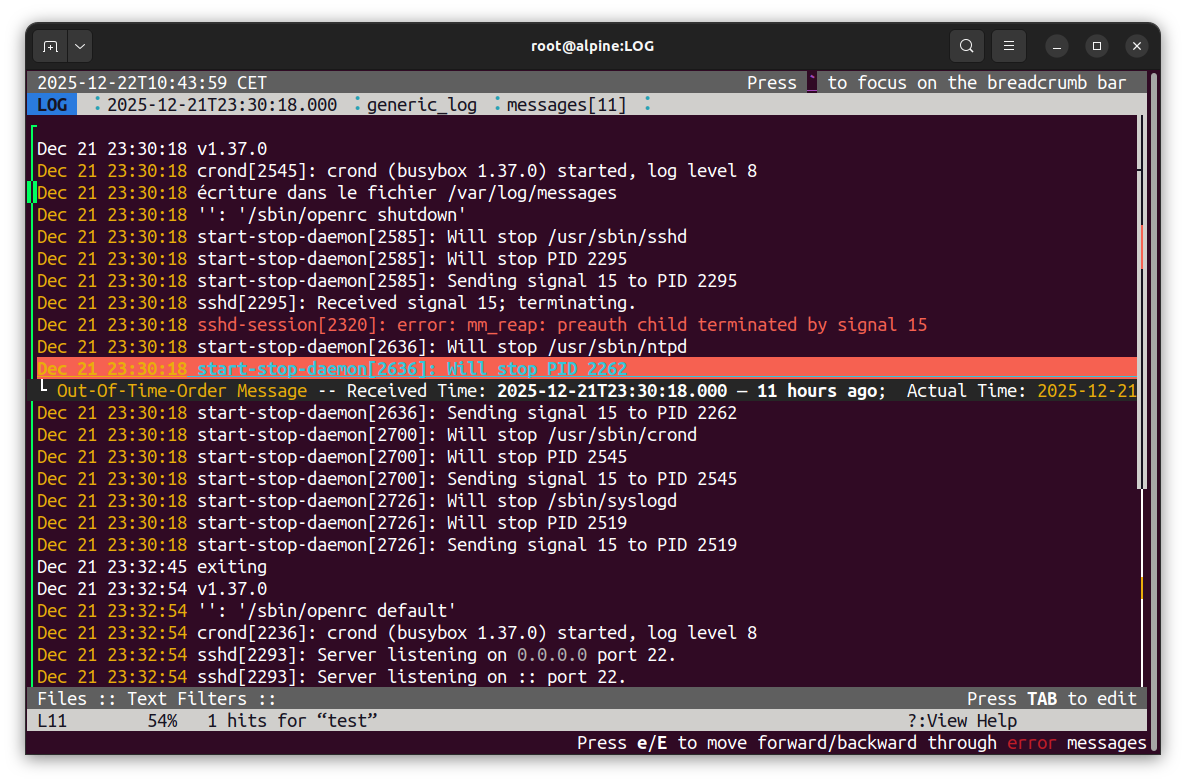 Voici 5 raccourcis pour survivre avec cet outil (pour le reste lisez la doc) :
Voici 5 raccourcis pour survivre avec cet outil (pour le reste lisez la doc) : -
/→ rechercher une chaîne ou une regex e→ aller à la prochaine erreur:→ prompt de commande lnav (auto-completion disponibletab);→ requête SQL sur les logsq→ quitter l’outil
Travail a rendre¶
Journalisation des accès¶
Services à analyser¶
Votre travail va consister a activer la journalisation pour le service sshd (authentification distante) A vous de décider un niveau de sévérité parmi :
- `DEBUG`
- `NOTICE`
- `WARNING`
-
justifier le choix en fonction :
- du volume de logs généré ;
- de l’intérêt pour l’analyse a posteriori ;
- des risques (bruit, données sensibles, surcharge).
Il n’existe pas de réponse unique attendue.
La cohérence du raisonnement prime sur le niveau choisi.
Documentation à utiliser (obligatoire)¶
Les choix doivent être appuyés sur la documentation officielle :
- OpenSSH – configuration de
sshd
https://man.openbsd.org/sshd_config - OpenSSH – option
LogLevel
https://man.openbsd.org/sshd_config#LogLevel - RFC 5424 – Syslog Protocol (sévérités)
https://www.rfc-editor.org/rfc/rfc5424.html
Toute justification doit pouvoir être reliée à l’un de ces documents.
Attendu¶
- identification des messages liés à
sshddans les logs ; - niveau de sévérité retenu pour chaque service ;
- justification écrite, courte et argumentée.
Aucun point n’est attribué à une configuration non expliquée ou copiée.
Observation complémentaire :¶
Générez plusieurs événements (connexions SSH, commandes logger) et affichez la taille du fichier de logs principal :
ls -lh /var/log/messages
Constat : le fichier /var/log/messages continue d’augmenter. Aucune limitation automatique de taille n’est visible. Aucune suppression ou archivage n’est observée.
Problème : si ce fichier continue de croître sans contrôle, le système reste fonctionnel… jusqu’au moment où l’espace disque devient une contrainte.
La journalisation, initialement conçue pour analyser les incidents peut alors devenir elle-même une source de panne. Ce risque n’est pas lié à syslogd, mais à l’absence de gestion du cycle de vie des logs.
Fait une petite recherche sur ce qu'est logrotate et expliquez son rôle dans un système Linux. Précisez :
- à quel moment
logrotateintervient ; - sur quoi il agit concrètement ;
- ce qu’il ne fait pas (par rapport à
syslogd).
Aucune configuration n’est attendue. La réponse doit être argumentée.